********
※LINE対応チャットボット版の
「LINEチャットボット屋」
いろんなチャットボットがあります。
ぜひ、ご覧ください!
***************

***************
AI for Scienceとは何か ビジネスを「実験対象」にするという発想
AI for Scienceとは、AIを使って科学的な仮説検証を加速させる取り組みのことです。
基本的な流れはシンプルです。まず仮説を立て、それをシミュレーションや実験で検証し、結果をもとに修正する。
この仮説―検証―反証のループ(Hypothesis–Falsification Loop)を高速に回すことが核心にあります。
通常、この考え方は物理学や生物学など自然科学の分野で語られます。
しかし今回はあえて視点を変え、ビジネスの価格競争を「実験対象」にしてみました。
理由はひとつ。
その方が面白そうだからです。
企業がどのように価格を決め、その結果どのような利益構造が生まれるのか。それをモデルの中で再現し、AIに仮説を出させて検証する方向で進めました。
価格競争モデルの設計 2社市場を実験環境にする
今回設計したのは、2社が同じ市場で価格を決め合うシンプルな競争モデルです。
消費者は価格差に応じてどちらかの企業を選びます。
ただし、価格が少し違うだけで急激に需要が変わるのではなく、滑らかに変化する仕組みにしています。
これにより、現実の市場に近い動きを再現できます。
このように構築されたモデルは、AI for Scienceにおける実験環境(Experimental Sandbox)の役割を果たします。
企業Aと企業Bはエージェントとして振る舞い、それぞれが価格を提案。
シミュレーションによって市場シェアと利益が計算され、その結果が次の意思決定に反映されるます。

仮説生成と反証ループ エージェントによる戦略進化
ここからがAI for Scienceの本番です。
各企業は、前世代の結果を分析し、「次はどの価格がよいか」という仮説を立てます。
そしてシミュレーションがその仮説を検証します。利益が下がれば、その仮説は反証されたと考え、次の戦略を修正します。
この仕組みは、反復的最適化(Iterative Optimization)であり、同時に反証駆動学習(Falsification-Driven Learning)とも呼ばれるそうです。
AIが自ら仮説を生成し、環境からのフィードバックを受けて戦略を進化させる。これはまさにAI for Scienceの実験的アプローチです。
シミュレーションを回すと、価格は固定されるのではなく、上下に動きながら最適解を探り始めます。
ある世代では値下げが有利になり、別の世代では値上げが利益を押し上げる。
こうした変化そのものが、戦略的相互作用の結果です。
最適反応の発見 「少し安い」が合理的になる理由
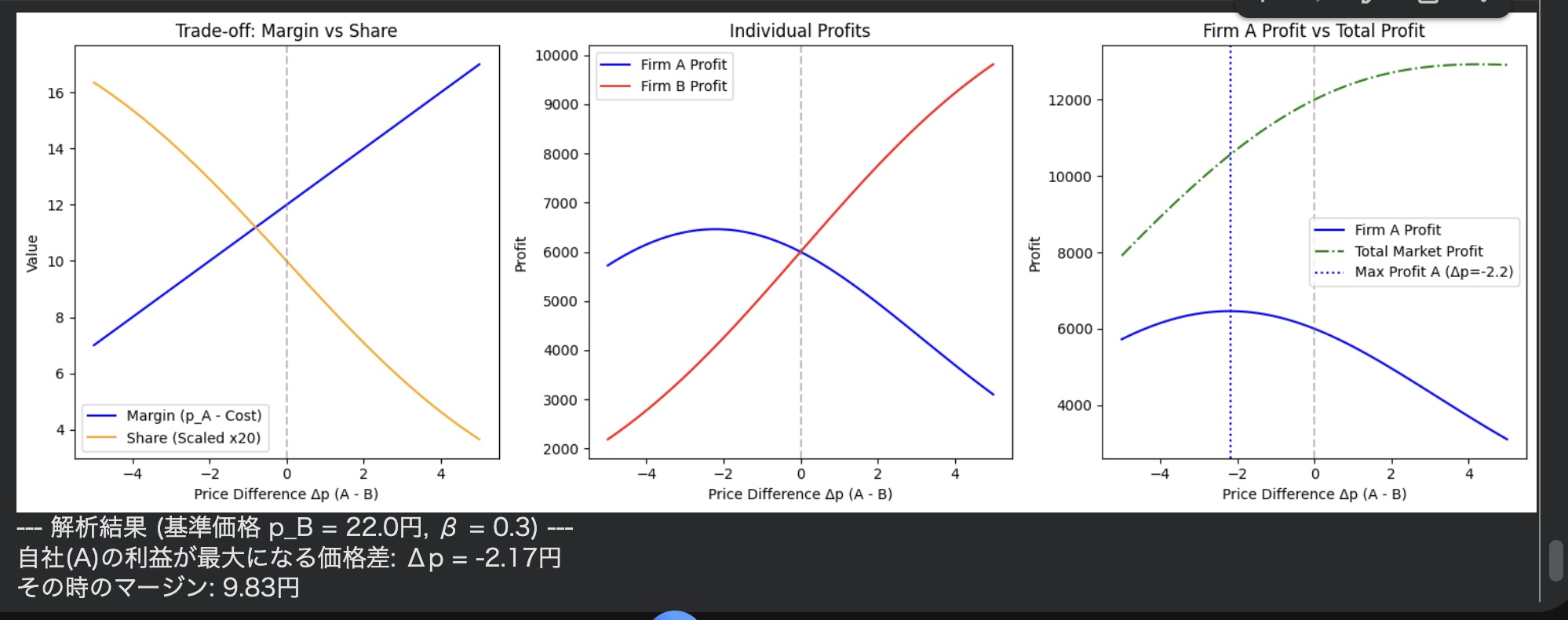
解析を進めると、興味深い結果が得られました。
競合が22円で販売している場合、自社が最も利益を得られるのは約2円安い価格設定であることが数値的に確認されたのです。
これは経済学でいう最適反応(Best Response)の同定にあたるそうです。
安すぎると1個あたりの利益が減り、高すぎると売れなくなる。そのバランス点が、約2円の価格差に現れました。
ここで重要なのは、AI for Scienceが単にシミュレーション結果を眺める段階から、さらに一歩前へと進んだことです。
最適価格差という具体的な数値が、戦略の合理性を説明する鍵になりました。
個別最適と市場最適のズレ
しかし、さらに深い問題が見えてきます。各企業が自社の利益を最大化しようとすると、価格は次第に下がり、市場全体の利益は縮小することがあります。
これは価格戦争の典型的な構造のようです。
この現象は、戦略的相互作用における均衡(Equilibrium)の問題らしいです。
個別最適の積み重ねが、必ずしも全体最適を生まない。ここに、経営戦略の難しさがあるのでしょう。
AI for Scienceの視点から見ると、これは単なるビジネス現象ではなく、「条件を変えれば結果はどう変わるのか」という感度分析(Sensitivity Analysis)の対象になるようです。
需要の反応の強さを変えればどうなるか、コスト構造を変えれば均衡は安定するのか。こうした問いを次々に検証できるのが、このアプローチの強みでしょう。
まとめ ビジネスも実験できる時代へ
今回の試みは、価格競争という身近なテーマを、AI for Scienceの枠組みで実験してみました。
仮説を立て、反証し、改良する。そのループを回すことで、戦略の背後にある構造が見えてきまます。
AI for Scienceは自然科学だけのものではありません。
経営や社会の問題もまた、仮説検証の対象になり得ます。
ビジネスを「実験可能なシステム」として扱うことで、感覚や経験に頼るだけでなく、構造を理解する道が開かれるのでしょう。
今後は、複数企業への拡張など、より高度な分析へと発展させることができます。
AIとシミュレーションを組み合わせることで、ビジネスの観点も科学的に探究できる時代に入っているのではないでしょうか。
今回使ったPythonコード
* 表示のバグでインテントが崩れています。
下記のコードを使用する場合は、お気に入りのAIにコピペして「インテント直して」と言ってください。
それと下記のコードはOpenAIのAPIを使っているので多少課金されます。
!pip install -q openai matplotlib
import numpy as np
import matplotlib.pyplot as plt
import re
import time
import getpass
from openai import OpenAI
# ==========================================
# 1. API・環境設定
# ==========================================
print("OpenAI APIキーを入力してください(入力内容は画面に表示されません):")
api_key = getpass.getpass()
try:
client = OpenAI(api_key=api_key)
print("APIキーの受付が完了しました。")
except Exception as e:
print(f"エラー: APIキーの初期化に失敗しました。詳細: {e}")
# ==========================================
# 2. 市場パラメータ設定
# ==========================================
TOTAL_DEMAND = 1000
COST = 10
BETA = 0.3
PRICE_MIN = 10
PRICE_MAX = 30
def calculate_market(p_A, p_B, beta=BETA, demand=TOTAL_DEMAND, cost=COST):
exp_A = np.exp(-beta * p_A)
exp_B = np.exp(-beta * p_B)
total_exp = exp_A + exp_B
share_A = exp_A / total_exp
share_B = exp_B / total_exp
profit_A = (p_A - cost) * share_A * demand
profit_B = (p_B - cost) * share_B * demand
return share_A, share_B, profit_A, profit_B
# ==========================================
# 3. LLM関連関数 (反証・仮説ステップ分離型)
# ==========================================
def extract_price(text):
numbers = re.findall(r"[-+]?\d*\.\d+|\d+", text)
if numbers:
price = float(numbers[-1])
return max(PRICE_MIN, min(PRICE_MAX, price))
return 20.0
def diagnose(firm_name, own_history, opponent_history):
"""
ステップ1: 過去のログから要因を分析し、反証を生成する
"""
if not own_history:
return "データが不足しているため、初期状態として処理します。"
prompt = f"""
あなたは市場における企業{firm_name}のデータアナリストです。
以下の過去の価格競争のログを分析し、現在の戦略の弱点と利益変動の要因を診断してください。
【自社({firm_name})の履歴】
{own_history}
【競合相手の履歴】
{opponent_history}
分析要件:
1. 前回の利益の増減が「シェアの変動」によるものか「マージン(価格-コスト)の変動」によるものかを特定すること。
2. 現在の自社戦略に対する反証(例: 価格を下げすぎている、相手のアンダーカットに無防備である等)を1段落で提示すること。
"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "あなたはデータ駆動型で論理的に分析を行う専門家です。"},
{"role": "user", "content": prompt}
],
temperature=0.3 # 分析は決定論的に寄せる
)
return response.choices[0].message.content
def propose_next_price(firm_name, diagnosis_result, own_history):
"""
ステップ2: 診断結果(反証)を受け取り、次ターンの価格(仮説)を生成する
"""
prompt = f"""
あなたは市場における企業{firm_name}の価格決定アルゴリズムです。
市場の総需要は1000、製品コストは10円です。価格は10〜30円の間で設定します。
【過去の自社履歴】
{own_history}
【直近の診断結果(反証)】
{diagnosis_result}
上記の分析に基づき、弱点を克服するための次ターンの価格を決定してください。
提案の理由(仮説)を述べた後、必ず文章の最後に「設定価格: X」という形式で数値を出力してください。
"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "あなたは利益最大化を目的とする経済学エージェントです。"},
{"role": "user", "content": prompt}
],
temperature=0.7 # 仮説生成には適度なランダム性を持たせる
)
response_text = response.choices[0].message.content
price = extract_price(response_text)
return price, response_text
# ==========================================
# 4. 進化ループ実行
# ==========================================
B_MODE = "llm"
FIXED_PRICE_B = 15.0
GENERATIONS = 5
history_log = {
"price_A": [], "price_B": [],
"share_A": [], "share_B": [],
"profit_A": [], "profit_B": [],
"delta_p": [], "total_profit": []
}
str_history_A = ""
str_history_B = ""
print("\nシミュレーションを開始します...")
for gen in range(GENERATIONS):
print(f"\n========== 世代 {gen + 1} ==========")
# --- 企業Aの処理プロセス ---
print(f"[企業Aの処理]")
diagnosis_A = diagnose("A", str_history_A, str_history_B)
print(f" > 診断完了: {diagnosis_A[:60]}...")
p_A, reason_A = propose_next_price("A", diagnosis_A, str_history_A)
# --- 企業Bの処理プロセス ---
if B_MODE == "fixed":
p_B = FIXED_PRICE_B
print(f"[企業Bの処理] 固定価格戦略 ({p_B}円)")
else:
print(f"[企業Bの処理]")
diagnosis_B = diagnose("B", str_history_B, str_history_A)
print(f" > 診断完了: {diagnosis_B[:60]}...")
p_B, reason_B = propose_next_price("B", diagnosis_B, str_history_B)
# --- 市場シミュレーション実行 ---
share_A, share_B, profit_A, profit_B = calculate_market(p_A, p_B)
delta_p = p_A - p_B
total_profit = profit_A + profit_B
history_log["price_A"].append(p_A)
history_log["price_B"].append(p_B)
history_log["share_A"].append(share_A)
history_log["share_B"].append(share_B)
history_log["profit_A"].append(profit_A)
history_log["profit_B"].append(profit_B)
history_log["delta_p"].append(delta_p)
history_log["total_profit"].append(total_profit)
print(f"\n[結果] 価格 -> A: {p_A:.2f}円, B: {p_B:.2f}円 (Δp: {delta_p:.2f}円)")
print(f"[結果] 利益 -> A: {profit_A:.2f}, B: {profit_B:.2f} (市場全体: {total_profit:.2f})")
str_history_A += f"世代{gen+1}: 自社価格={p_A:.2f}, 相手価格={p_B:.2f}, 自社シェア={share_A:.2f}, 自社利益={profit_A:.2f}\n"
str_history_B += f"世代{gen+1}: 自社価格={p_B:.2f}, 相手価格={p_A:.2f}, 自社シェア={share_B:.2f}, 自社利益={profit_B:.2f}\n"
time.sleep(2) # 複数回APIを呼ぶため少し長めに待機
# ==========================================
# 5. ログの可視化
# ==========================================
epochs = range(1, GENERATIONS + 1)
plt.figure(figsize=(12, 10))
plt.subplot(2, 2, 1)
plt.plot(epochs, history_log["price_A"], label='Firm A Price', marker='o')
plt.plot(epochs, history_log["price_B"], label='Firm B Price', marker='x')
plt.title('Price Evolution')
plt.xlabel('Generation')
plt.ylabel('Price')
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(epochs, history_log["delta_p"], label='Δp (A - B)', marker='s', color='purple')
plt.axhline(0, color='gray', linestyle='--')
plt.title('Price Difference (Δp = p_A - p_B)')
plt.xlabel('Generation')
plt.ylabel('Price Difference')
plt.legend()
plt.subplot(2, 2, 3)
plt.plot(epochs, history_log["share_A"], label='Firm A Share', marker='o')
plt.plot(epochs, history_log["share_B"], label='Firm B Share', marker='x')
plt.title('Market Share')
plt.xlabel('Generation')
plt.ylabel('Share')
plt.ylim(0, 1)
plt.legend()
plt.subplot(2, 2, 4)
plt.plot(epochs, history_log["profit_A"], label='Firm A Profit', marker='o')
plt.plot(epochs, history_log["profit_B"], label='Firm B Profit', marker='x')
plt.plot(epochs, history_log["total_profit"], label='Total Market Profit', marker='D', color='green', linestyle='-.')
plt.title('Profit Evolution (Individual & Total)')
plt.xlabel('Generation')
plt.ylabel('Profit')
plt.legend()
plt.tight_layout()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
# ==========================================
# 1. 市場パラメータと関数
# ==========================================
TOTAL_DEMAND = 1000
COST = 10
BETA = 0.3
def calculate_market(p_A, p_B, beta=BETA, demand=TOTAL_DEMAND, cost=COST):
exp_A = np.exp(-beta * p_A)
exp_B = np.exp(-beta * p_B)
total_exp = exp_A + exp_B
share_A = exp_A / total_exp
share_B = exp_B / total_exp
profit_A = (p_A - cost) * share_A * demand
profit_B = (p_B - cost) * share_B * demand
return share_A, share_B, profit_A, profit_B
# ==========================================
# 2. 価格差(Δp)スイープ実験
# ==========================================
fixed_p_B = 22.0 # 企業Bの価格を固定(基準価格)
delta_p_array = np.linspace(-5, 5, 100) # Δp (A - B) を -5 から +5 まで連続的に変化
# 記録用リスト
margins_A = []
shares_A = []
profits_A = []
profits_B = []
total_profits = []
for dp in delta_p_array:
p_A = fixed_p_B + dp
# 市場計算
s_A, s_B, prof_A, prof_B = calculate_market(p_A, fixed_p_B)
# 指標の分解と記録
margin_A = p_A - COST
margins_A.append(margin_A)
shares_A.append(s_A)
profits_A.append(prof_A)
profits_B.append(prof_B)
total_profits.append(prof_A + prof_B)
# ==========================================
# 3. ログの可視化 (曲線による構造分析)
# ==========================================
plt.figure(figsize=(15, 5))
# ① マージンとシェアのトレードオフ
plt.subplot(1, 3, 1)
plt.plot(delta_p_array, margins_A, label='Margin (p_A - Cost)', color='blue')
# 視認性のためシェアをスケールして重畳表示(本来は0.0〜1.0)
plt.plot(delta_p_array, [s * 20 for s in shares_A], label='Share (Scaled x20)', color='orange')
plt.axvline(0, color='gray', linestyle='--', alpha=0.5) # 価格差0のライン
plt.title('Trade-off: Margin vs Share')
plt.xlabel('Price Difference Δp (A - B)')
plt.ylabel('Value')
plt.legend()
# ② 自社利益と相手利益の推移
plt.subplot(1, 3, 2)
plt.plot(delta_p_array, profits_A, label='Firm A Profit', color='blue')
plt.plot(delta_p_array, profits_B, label='Firm B Profit', color='red')
plt.axvline(0, color='gray', linestyle='--', alpha=0.5)
plt.title('Individual Profits')
plt.xlabel('Price Difference Δp (A - B)')
plt.ylabel('Profit')
plt.legend()
# ③ 個別利益 vs 市場全体利益
plt.subplot(1, 3, 3)
plt.plot(delta_p_array, profits_A, label='Firm A Profit', color='blue')
plt.plot(delta_p_array, total_profits, label='Total Market Profit', color='green', linestyle='-.')
plt.axvline(0, color='gray', linestyle='--', alpha=0.5)
# Aの利益が最大になるΔpを算出してプロット
max_profit_A_idx = np.argmax(profits_A)
optimal_dp = delta_p_array[max_profit_A_idx]
plt.axvline(optimal_dp, color='blue', linestyle=':', label=f'Max Profit A (Δp={optimal_dp:.1f})')
plt.title('Firm A Profit vs Total Profit')
plt.xlabel('Price Difference Δp (A - B)')
plt.ylabel('Profit')
plt.legend()
plt.tight_layout()
plt.show()
# 数値の出力
print(f"--- 解析結果 (基準価格 p_B = {fixed_p_B}円, β = {BETA}) ---")
print(f"自社(A)の利益が最大になる価格差: Δp = {optimal_dp:.2f}円")
print(f"その時のマージン: {fixed_p_B + optimal_dp - COST:.2f}円")
print(f"その時のシェア: {shares_A[max_profit_A_idx]:.2f}")
****************
最近のデジタルアート作品を掲載!
X 旧ツイッターもやってます。
https://x.com/ison1232
インスタグラムはこちら
https://www.instagram.com/nanahati555/
***************